What is the CAP theorem really about?
Thu Feb 11 2021tags: programming computer science self study notes public 6.824 MIT distributed systems featured
Introduction
The NUS folks and I were discussing the Spinnaker paper while doing MIT's distributed systems course. We realised that we kept going around in circles talking about Spinnaker's guarantees: apparently DynamoDB is an "AP" system, but Spinnaker is a "CA" system? Is that right? What is a "CA" system? Can such a system exist? What does "partition tolerance" even mean?
The discussion got hopelessly muddled because we didn't really understand what the CAP theorem was really about. After very helpful discussions with Liang Jun, Julius and Wei Neng, I'm writing this post to (try to) shed some light on the topic, and dispel some common misconceptions I heard (and previously held!) during the discussion.
EDIT 2021-02-16: I just came across this wonderful CAP FAQ on the-paper-trial.org which has basically written everything I have here, but better! [1] I wish I had stumbled across this earlier. But I'm happy that what I have written here is correct and vindicated by this FAQ.
The CAP theorem is NOT "pick two out of three"!
One common mis-definition of CAP is:
You can only pick two out of consistency, availability, and partition tolerance.
This implies that there are "CA" systems, "CP" systems, and "AP systems". In fact, this couldn't be further from the truth. As a system designer you can't choose not to be partition-tolerant. Rather, almost all systems are (or can easily be) CA in the absence of partitions, and systems must choose to give up either C (Dynamo, Cassandra) or A (Spinnaker) in the presence of P. More on this later, but first, some definitions:
Consistency: What "consistency" is is actually super nontrivial
I often hear consistency defined as "a system is consistent if any request received by the system returns either the correct result or an error." But what is the "correct" result? It's too handwavy for my taste. Upon reading up more, I learned that there's strong consistency, linearisable consistency, timeline consistency, eventual consistency, and who knows what else.
I like the following two more formal treatments of consistency that show that there's actually a universe of consistencies. Jepsen has a clickable map and excellent definitions and Aphyr has a very readable treatment of the matter.
So which version of consistency do we want? The CAP theorem actually means linearisable consistency, or linearisability. This is quite a strong definition of consistency (and in fact it's often called "strong consistency"). The usual definition of linearisability is stated as follows:
Linearisable Consistency: A system is linearisable if all operations appear to take place atomically in an order consistent with the real-time ordering of those operations: e.g., if operation A completes before operation B begins, then B should logically take effect after A.
The real definition given by Herlihy and Wing (1990) is a tad more complicated. I'll go through it in the appendix.
Availability: thankfully easier to define
Availability: A system is available if every request received by a non-failing node in the system results in a response.
Note here "non-failing node!" This is key. We'll use this later.
Partition-tolerance: You need to define partition-tolerance with respect to something
A system must be partition-tolerant with respect to consistency or availability---it can't be just "partition-tolerant".
Partition Tolerance: A system is part ition-tolerant with respect to X if {condition for X} still holds when the set of nodes are split into any number of disjoint subsets that cannot communicate with any elements outside that subset.
Closely related, but not identical, is the notion of fault-tolerance:
Fault Tolerance: A system is fault-tolerant with respect to X up to F failures if {condition for X} still holds when any of F nodes fail.
Putting it all together: stating the CAP theorem properly
Almost all systems are CA in the absence of partitions or failures. We should therefore only talk about the CAP theorem in the presence of faults or network partitions. More precisely, when you have a network partition, you can only have one of linearisability (consistency) or availability.
Here's aphyr again:
Providing consistency and availability when the network is reliable is easy. Providing both when the network is not reliable is provably impossible. If your network is not perfectly reliable–and it isn’t–you cannot choose CA. This means that all practical distributed systems on commodity hardware can guarantee, at maximum, either AP or CP.
Paxos/Spinnaker/Raft are C in the presence of partitions, CA when the number of failing servers is less than half, and C when the number of failing servers is more than half.
More interestingly, because consistency is a spectrum (ish), as you start weakening the definition of consistency, you will eventually get availability AND "consistency" for some sufficiently weak definition of consistency.
Here's a nice map of the CAP theorem for different definitions of C. The ones shaded in red cannot be fully available:
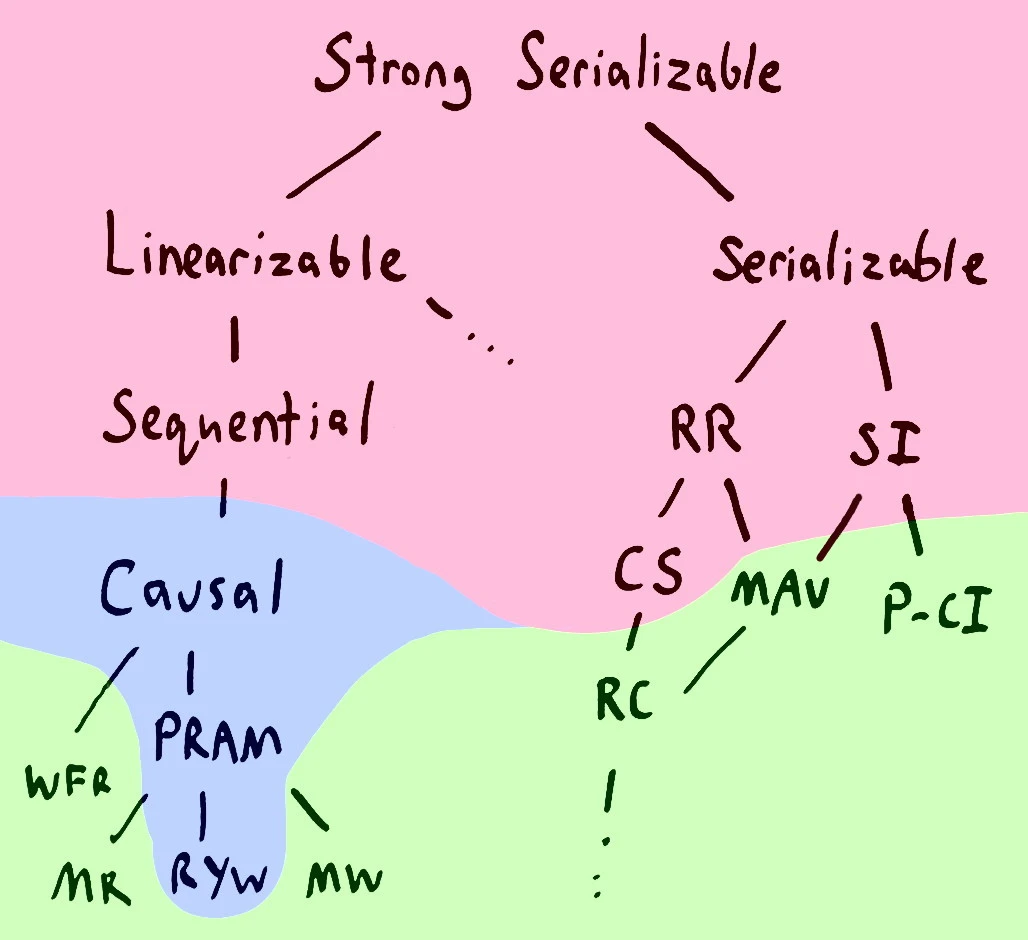
The nicer version is available at the Jepsen website.
Partition-tolerance is NOT fault-tolerance!
Something I kept hearing during the discussions is that "network partitions are basically like node failures". That's not quite true! It is kind of true in a practical sense that if a node stops receiving and sending messages to the rest of the cluster because it's behind a network partition, that node might as well be failing.
But it does matter for the finicky definition of the CAP theorem, because availability is about queries on non-failing nodes. A node can be behind a network partition but not be failing, in which case that node has to return a value to be available (provided it can be reached by the client). Coda Hale made this mistake in his post You Can't Sacrifice Partition Tolerance., and made a correction:
... Therefore, considering a node failure as a partition results in an obviously inappropriate CAP theorem conclusion [emphasis mine].
He is correct: a dead (or wholly partitioned) node can receive no requests, and so the other nodes can easily compensate without compromising consistency or availability here. My error lies in forgetting that Gilbert and Lynch’s formulation of availability requires only non-failing nodes to respond, and that without ≥1 live nodes in a partition there isn’t the option for split-brain syndrome. I regret the error and thank both him and Dr. Brewer for pointing this out
Furthermore, there's a sense in which partition-tolerance is a stronger condition than fault-tolerance. If a system is partition-tolerant with respect to availability it is also fault-tolerant with respect to availability, but the reverse is not true. Systems like Raft or Paxos are fault-tolerant (with respect to availability), but not partition-tolerant, because that's literally impossible. Here's a rough sketch of a proof:
Claim: if a system is partition-tolerant with respect to availability, it is also fault-tolerant with respect to availability,
Proof:
Consider a partition where any F nodes are in individual disjoint subsets of size 1 and all other nodes are in another subset:
Since the system is partition-tolerant with respect to availability, every request received by any node in any subset results in a response. A fortiori, every request received by any node in the subset results in a response.
Now consider if nodes through fail. The system is available if every request received by any non-failing node results in a response. Therefore, the system is available if every request received by any node through results in a response. But we know that every request received by any node in the subset results in a response. Therefore, the system is still available despite the failure of nodes. QED.
Note that the converse is not true! Counterexample: Paxos/Raft are fault-tolerant with respect to availability up to node failures. But if one node is in its own partition with the client and you query that node, it will never be able to get quorum and will not return you a result--hence, it's not partition-tolerant.
Conclusion
TBD
References
- Coda Hale (2010). You Can't Sacrifice Partition Tolerance.
- Herlihy and Wing (1990). Linearizability: A Correctness Condition for Concurrent Objects
- Jepsen (2018) Consistency Models
- Kyle Kingsbury, a.k.a Aphyr (2014). Strong consistency models
- Robinson (2013), on The Paper Trail. The CAP FAQ.
Appendix A: linearisability
Linearisability comes from the Herlihy and Wing (1990) paper. This is my attempt at explaining it simply because there's lots of notation, and my God do they do a bad job of explaining simply.
Linearisability is fundamentally about a history. We'll see how we will be able to expand this to objects and systems later. But what is a history? Let's use an example to demonstrate.
Suppose we have a queue object called r
(why not call it q? Cause I'm gangsta that way).
The queue object supports the operation
enqueue x, which enqueues some value x, and
dequeue, which returns the first object in the queue.
Most importantly, because we're talking about concurrency,
there can be different processes calling functions
on the same object.
We use the notation r (Enq(x), B) to denote
process B calling enqueue with the argument x
on the object r.
Now these operations take time.
We can split it up into two parts:
the time when you call the function
(enqueue or dequeue), and the time when you receive a response.
Let's use the notation r (OK(x), A) to denote
process A receiving a response to its latest
function call with the result x.
So, a history is basically a log of all these operations, in time-ascending order (earliest first). Let's use an example to illustrate. Suppose processes A and B concurrently enqueue two values. While process A started first, process B's call ran quicker and returned earlier. Then the history would look like this:
r (Enq(x), A) // process A starts calling first...
r (Enq(x), B)
r (OK, B) // but process B gets a response first!
r (OK, A)
So that's a history. In particular, this is a concurrent history, because we can have function calls returning out-of-order: an earlier call might get a response after a later call. This is in contrast with a sequential history, where every call must immediately be followed by its matching response.
With those definitions down, we can then define linearisability.
Linearisability: An concurrent history is linearisable if you can rearrange it into a sequential history while following the following rules:
- You must not violate the invariants of the object (e.g. a queue is FIFO, a stack is LIFO, etc.)
- You must respect real-time ordering:
If in the concurrent history you have
Response_1return beforeCall_2, you may never moveCall_2-Response_2beforeCall_1-Response_1.
Here's an example. The following history is linearisable,
r (Enq(x), B)
r (Enq(y), A)
r (OK, A)
r (OK, B)
r (Deq(), A)
r (Deq(), B)
r (OK(y), B)
r (OK(x), A)
because it can be rearranged into the following sequential ordering:
r (Enq(x), A)
r (OK, A)
r (Enq(y), B)
r (OK, B)
r (Deq(), A)
r (OK(x), A)
r (Deq(), B)
r (OK(y), B)
However, the following history is not linearisable,
r (Enq(x), A)
r (OK, A)
r (Enq(y), B)
r (Deq(), A)
r (OK, B)
r (OK(y), A)
because the only sequential reordering breaks one of the rules.
If you moved forward r (OK, B)
(the only possible rearrangement)
you'd get the following:
r (Enq(x), A)
r (OK, A)
r (Enq(y), B)
r (OK, B)
r (Deq(), A)
r (OK(y), A)
But here is enqueued first, but is dequeued first, which violates the FIFO principle.
Note that if you didn't have rule number 2 (that rearrangements must follow the time ordering) you could get a valid history:
r (Enq(y), B)
r (OK, B)
r (Enq(x), A)
r (OK, A)
r (Deq(), A)
r (OK(y), A)
And in fact this is Lamport's sequential consistency:
a concurrent history is sequentially consistent
if you can rearrange it any-which-way to get a consistent
sequential history.
(EDIT: this is actually serialisability, not sequential
consistency. Serialisability allows you to arrange it any-which-way:
sequential consistency allows you to rearrange it provided you follow
a time order within a process.
Linearisability needs you to follow a time order between all processes.
Thanks to Julius and Zongran for pointing this out!)
But this rearrangement is not allowed under linearisability
because in the concurrent history
r (OK, A) happened before r (Enq(y), B).
So what does this have to do with distributed systems and consistency?
The idea here is that a distributed system is made up of objects. Herlihy and Wing show that a system is linearisable (ergo "strongly consistent") if all its objects are linearisable.
But we've been talking about histories. how can objects be linearisable? Herlihy and Wing just whack definitions:
A set S of histories is prefix-closed if whenever H is in S, every prefix of H is also in S. A single-object history is one in which all events are associated with the same object. A sequential specification for an object is a prefix-closed set of single-object sequential histories for that object. ... A linearisable object is one whose concurrent histories are linearisable with respect to some sequential specification.
Eureka! Or maybe not, if you're not mega big brain. Let me try to unpack this in normal-people-speak without all the definitions.
Consider all the possible "valid" sequential histories of an object (that is, histories that don't break the invariants of the object, like popping a value before it's pushed, or dequeuing a value that wasn't first in). This set is technically finite since histories must be of bounded length, and you can't push unbounded values (maybe the max value is uint256 or whatever).
Basically, an object is linearisable if any valid concurrent history (a concurrent history that could actually happen) can be rearranged (following the rules) into a valid sequential history. So a queue is not linearisable, because we've just constructed examples of valid concurrent histories that are not linearisable. But a mutex would be linearisable, for instance.
So there we have it: the formal definition of linearisability. The worst thing is that it's not really helpful, because it's much easier to reason with the entirely equivalent "atomic" definition. But I hope it was interesting all the same.
I believe I explain linearisability better: I don't really get his explanation about "external communication being respected". ↩︎